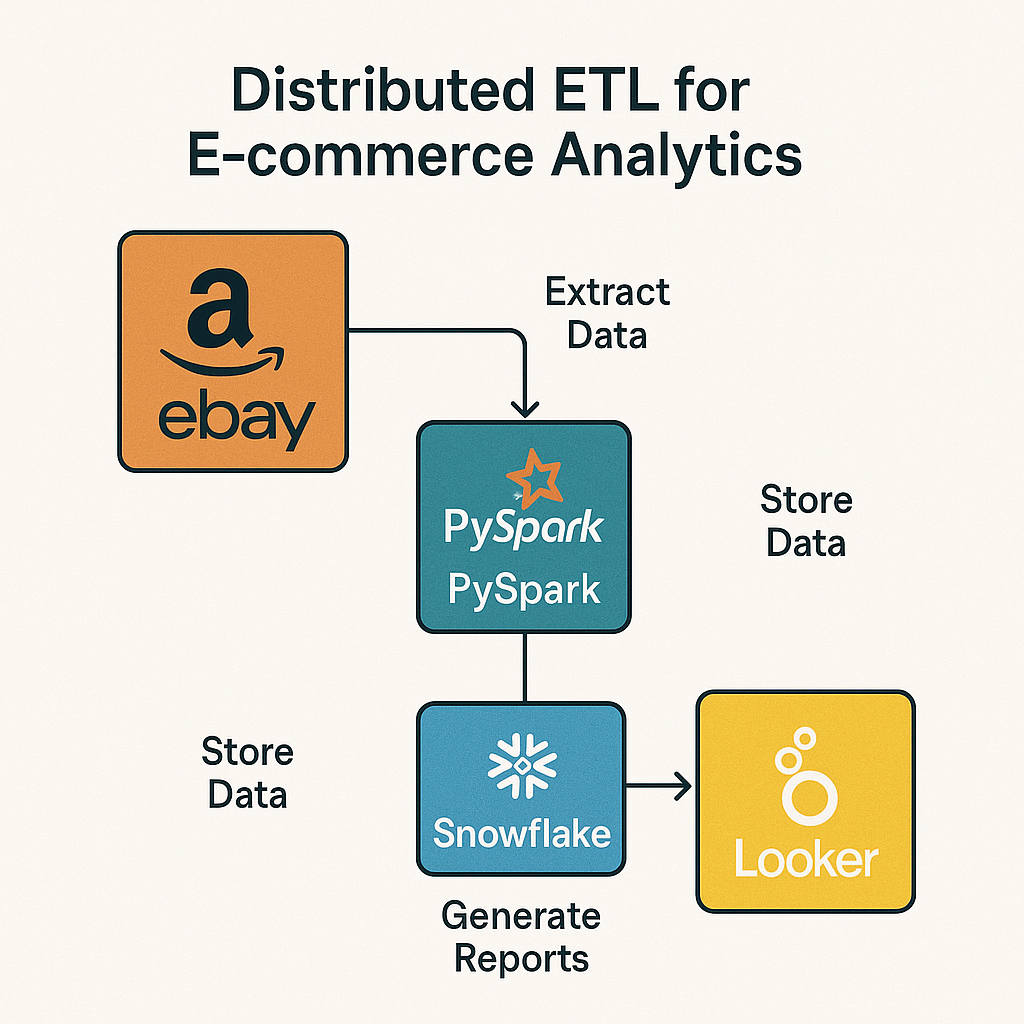
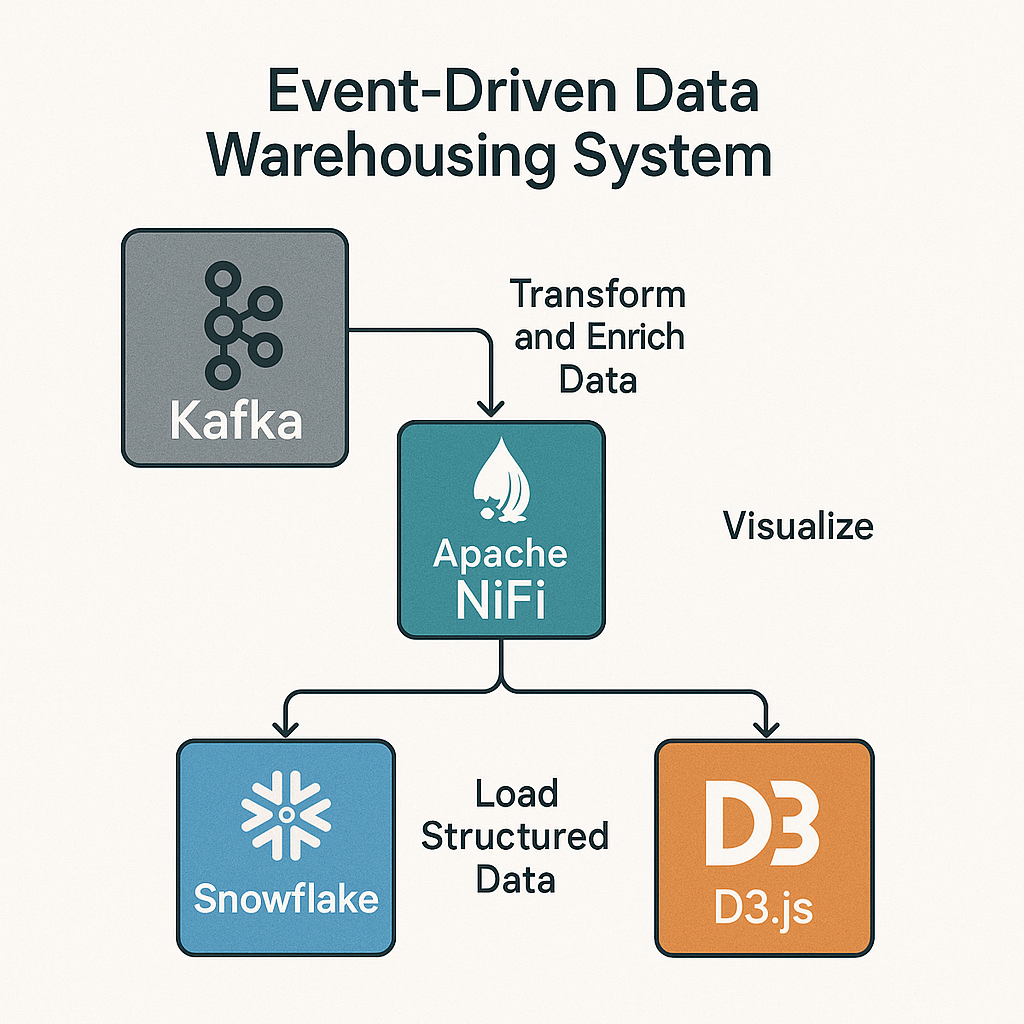
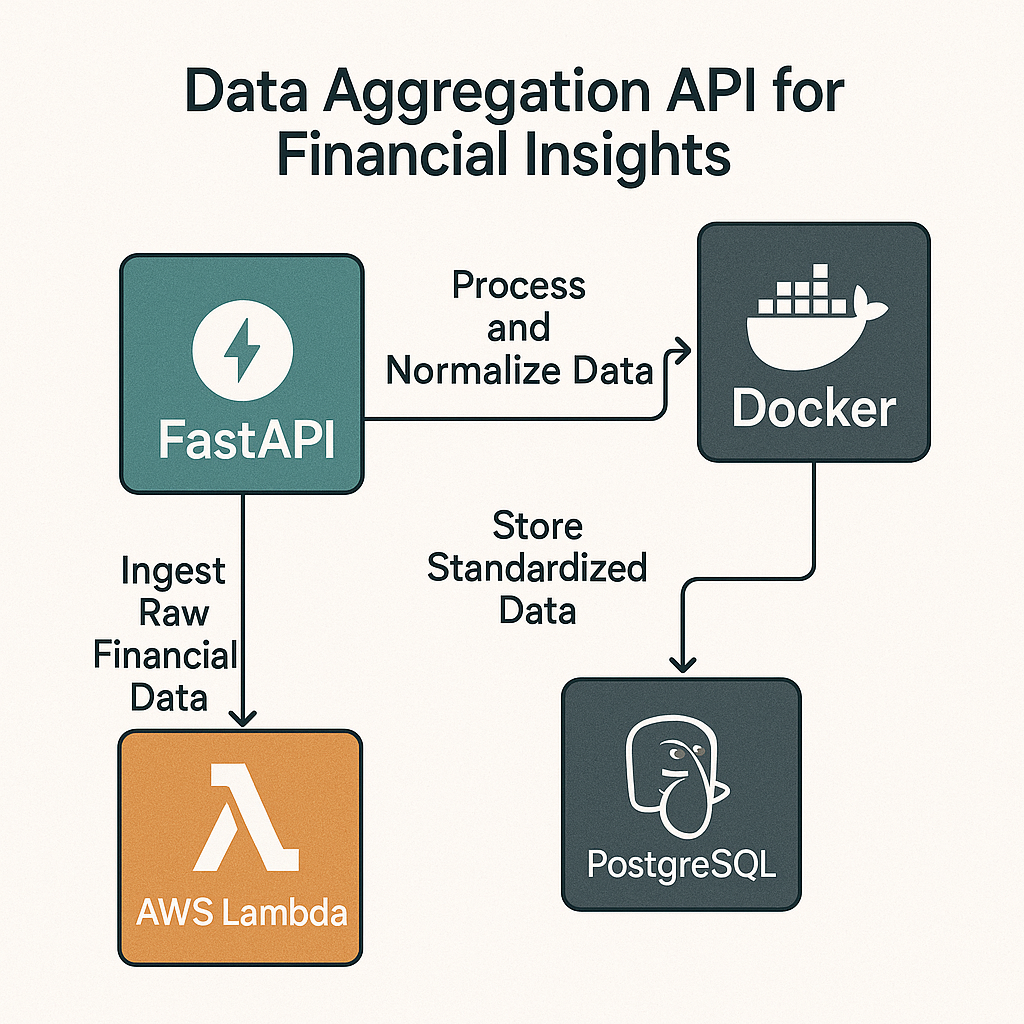
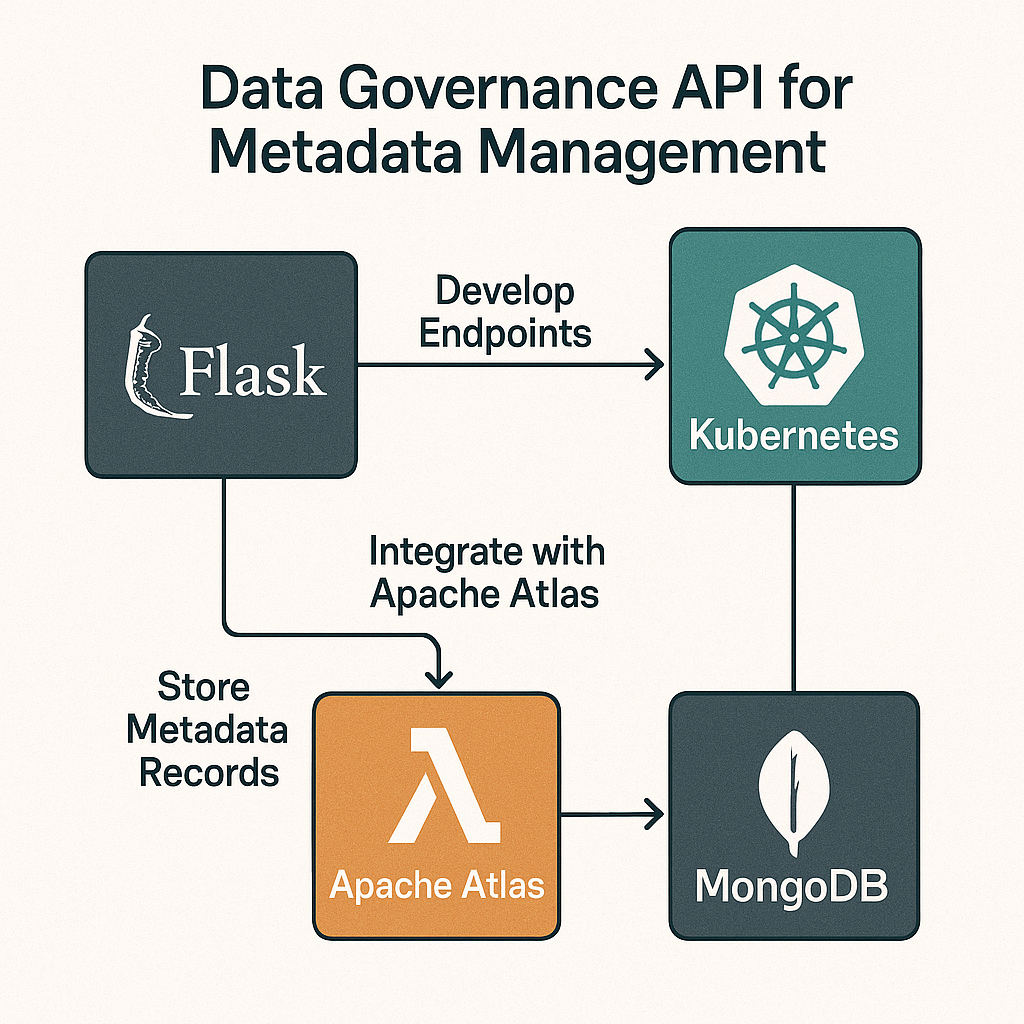
About me
AWS Certified Data Engineer with around 4 years of experience in designing scalable data pipelines and cloud-based solutions. Skilled in using Python, AWS, and big data technologies like Apache Spark and Kafka to build efficient, high-performance data processing systems.
Proficient in implementing ETL workflows, real-time data streaming, and automated data integration across multi-cloud environments. Experienced in leveraging AWS Glue, Snowflake, and Airflow to optimize data pipelines and ensure seamless data flow.
Passionate about improving data accessibility and operational efficiency through automation and robust architecture. Proven track record of reducing processing times, enhancing data quality, and enabling data-driven insights.
What i'm doing
-

Programming and Scripting
Writing efficient code for data manipulation, pipeline automation, and ETL tasks.
-

Data Pipelines and ETL Tools
Building and orchestrating data workflows to extract, transform, and load data.
-

Data Warehousing and Storage
Managing structured and unstructured data in scalable, high-performance storage solutions.
-

Cloud Platforms and Tools
Leveraging cloud infrastructure to build, deploy, and maintain data processing applications.
Recommendations
-

Naoki Yamaguchi
Atul Tiwari is an outstanding engineer and a fantastic colleague. We hired him as a fresh graduate, and it quickly became clear we were lucky—his skills in data scraping, database management, cloud services, and Python were impressive. Beyond technical abilities, he brought energy, patience, and leadership, which led to his promotion to Scrum Leader within six months. I’d gladly work with him again if the chance arises.
-
Amandeep Kaur Sandhu
Atul is a standout student with a deep passion for Computer Science. During his undergraduate studies, he consistently delivered high-quality work and exceeded expectations. His research projects were impressive and even presented at national and international conferences. Atul’s dedication, teamwork, and ability to manage multiple responsibilities make him a strong candidate for any graduate program. I’m confident he will excel in the field of Computer Science and Engineering.
-

Muhammad Thouseef
Working with Atul was one of the highlights of my time at Propre. He's not only a skilled data engineer with deep knowledge of pipelines, cloud platforms, and Python—but also someone you can always count on. Whether we were debugging a tricky job in Spark or collaborating on sprint planning, Atul brought a calm, focused energy to the team. He's collaborative, proactive, and always ready to help. I’d jump at the chance to work with him again!